Customer Churn Prediction - ML project
Goal:
Develop an accurate churn prediction model for a telecommunications company to identify customers likely to churn.
Aimed to demonstrate analysis, machine learning, and data science skills.
Result:
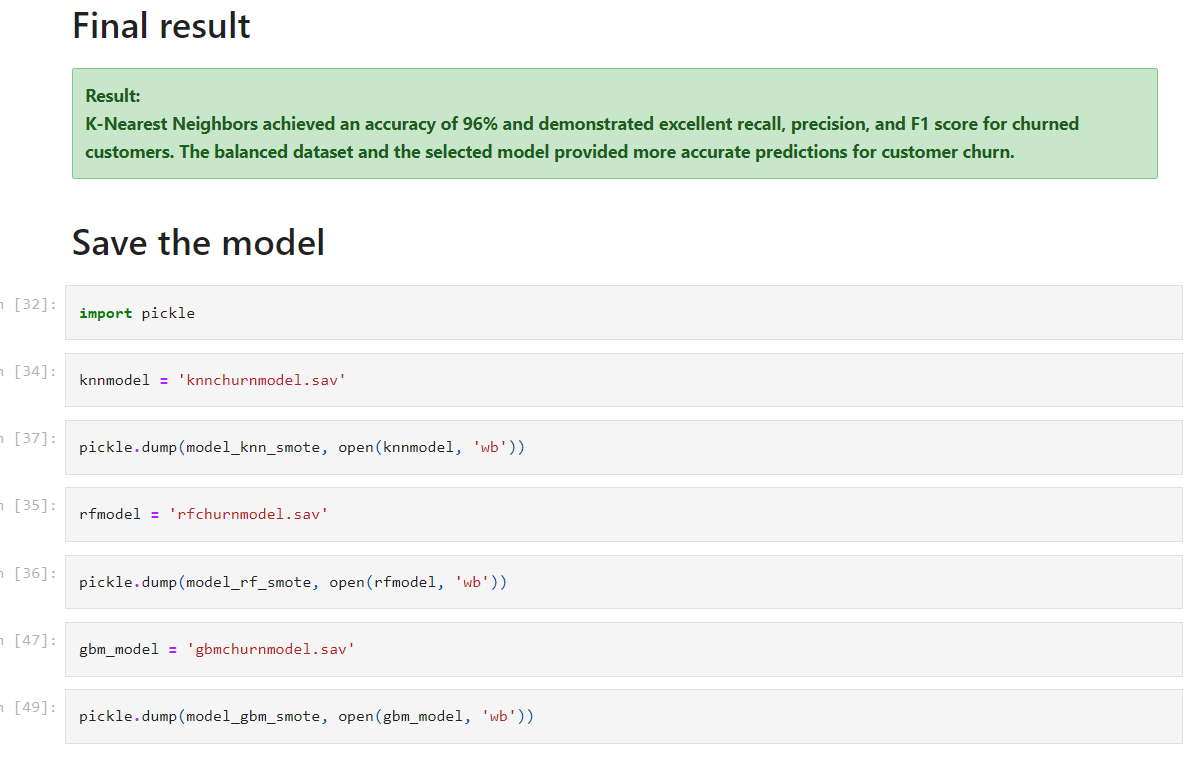
Achieved 96% accuracy in predicting customer churn, enabling the company to proactively address retention strategies and reduce churn rate.
Scope: The developed churn prediction model can serve as the foundation for creating a web application or API that allows users to input customer information and receive predictions about potential churn.
Duration:
Completed within 7 days.
This project was undertaken as a personal project to showcase the feasibility of developing a churn prediction model within a limited timeframe.
Industry projects could extend due to thorough data cleaning, iterative model improvement, testing, stakeholder collaboration, and customization.
Approach
Understand Customer Behavior (EDA)
Churn indicates how many customers cancel taking service within a certain time compared to active customers. This requires strong prediction tools.
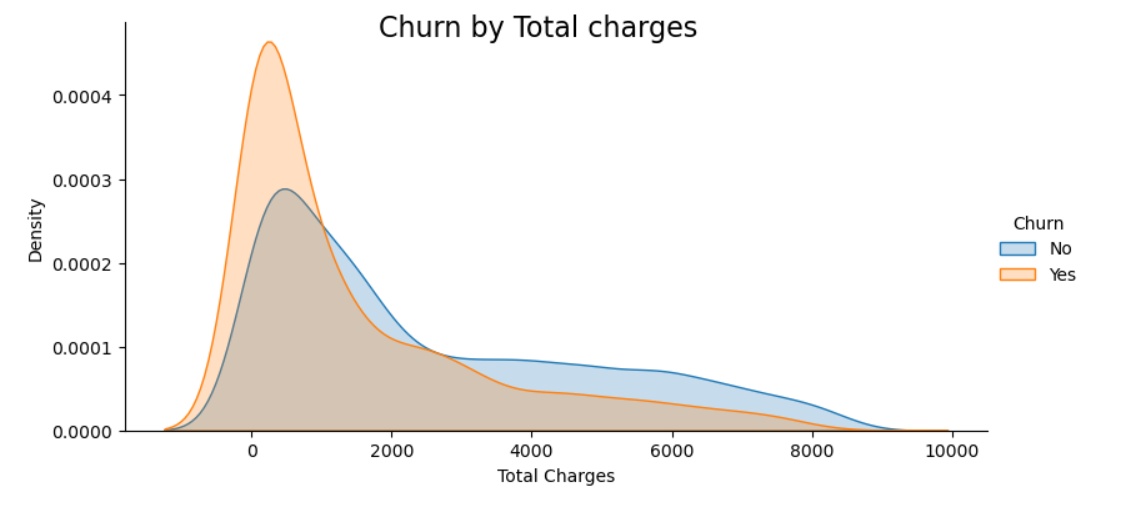
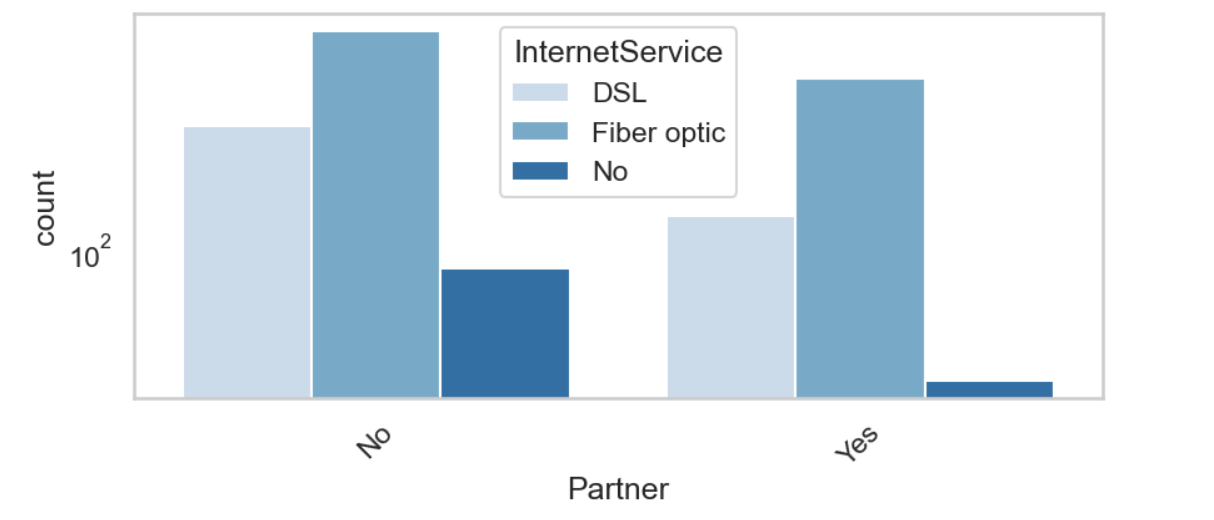
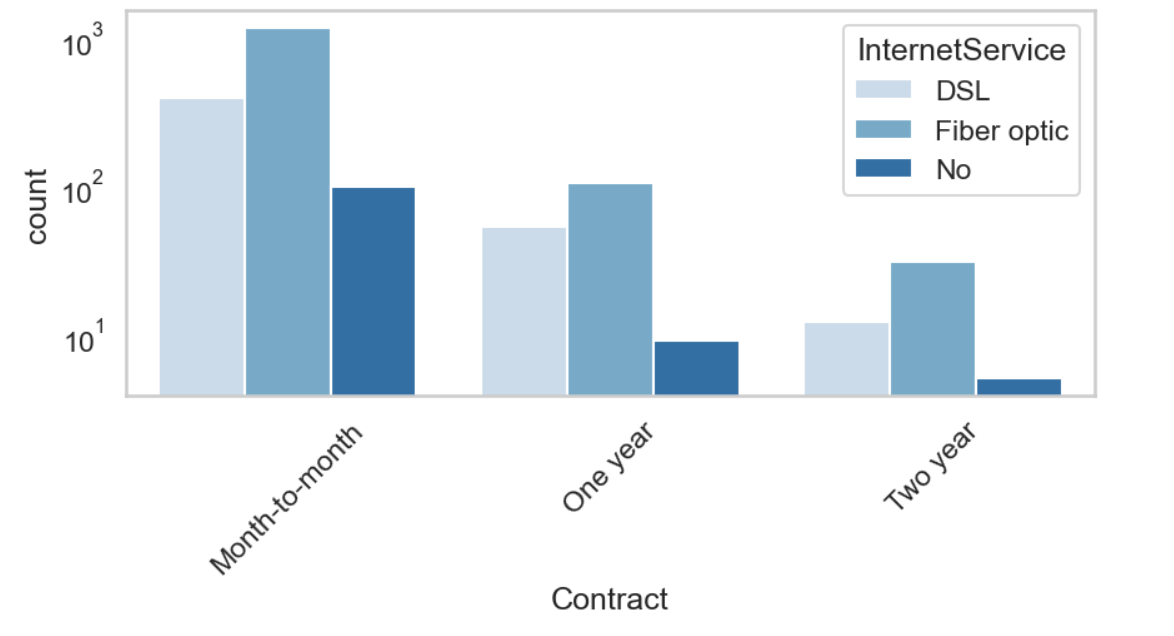
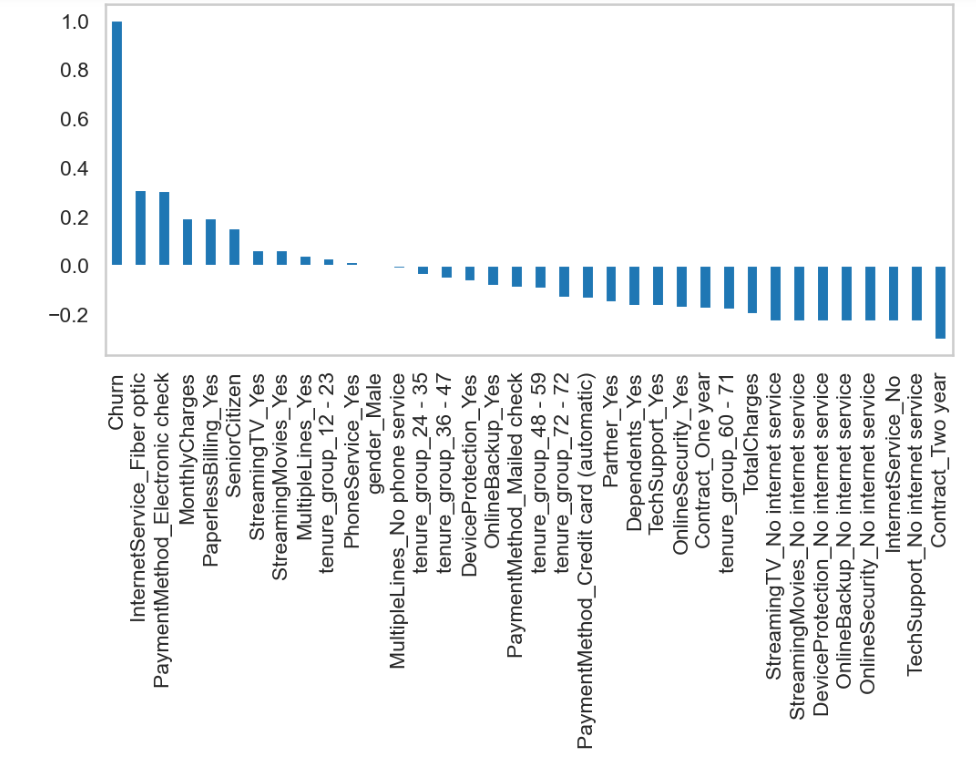
This project aimed to predict customer churn, where customers stop using a service. Through in-depth Exploratory Data Analysis (EDA), I comprehensively explored customer behavior and associated attributes. I used graphs and numbers to learn what things might make customers leave. This helped build a smart model that can tell us when a customer might leave. This is useful for businesses to prevent customers from leaving and offer better service.
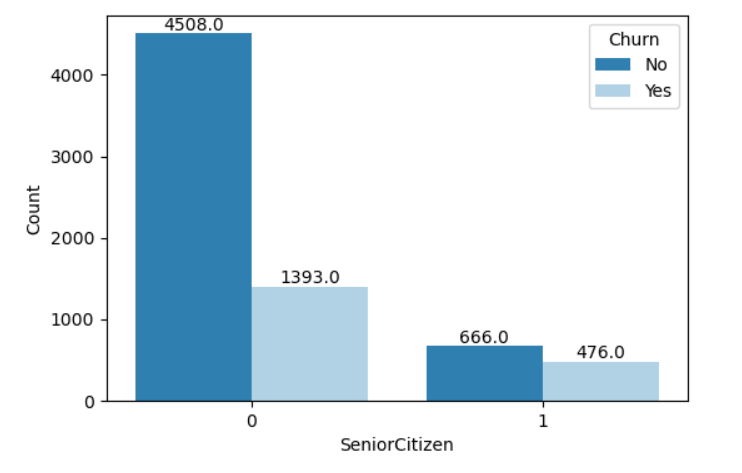
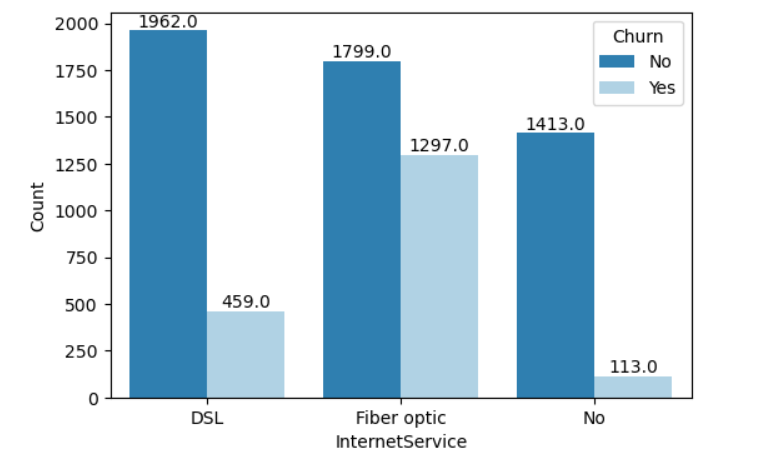
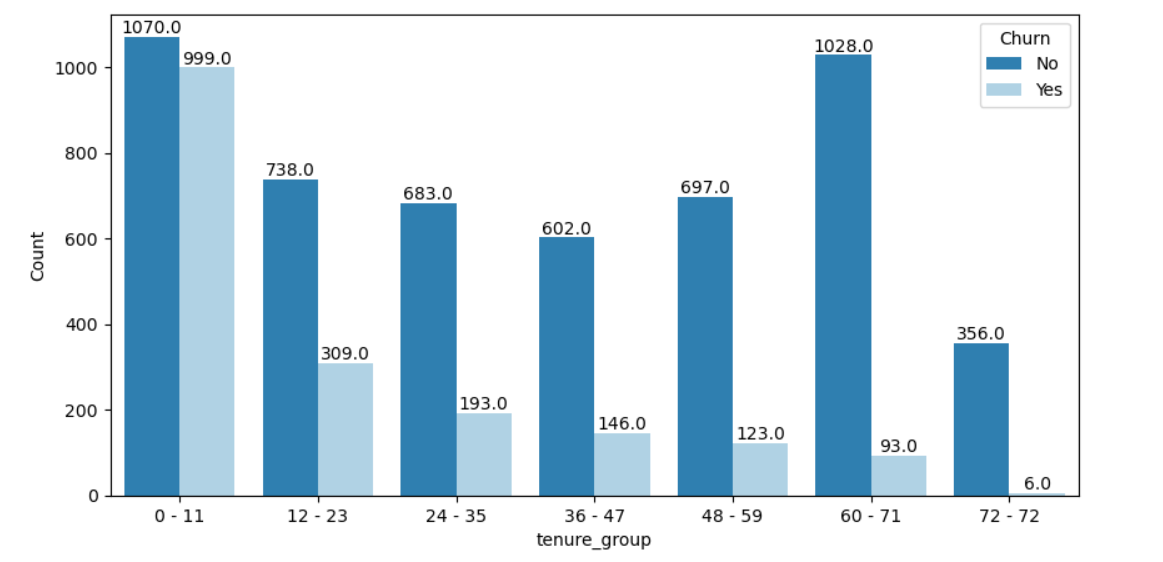
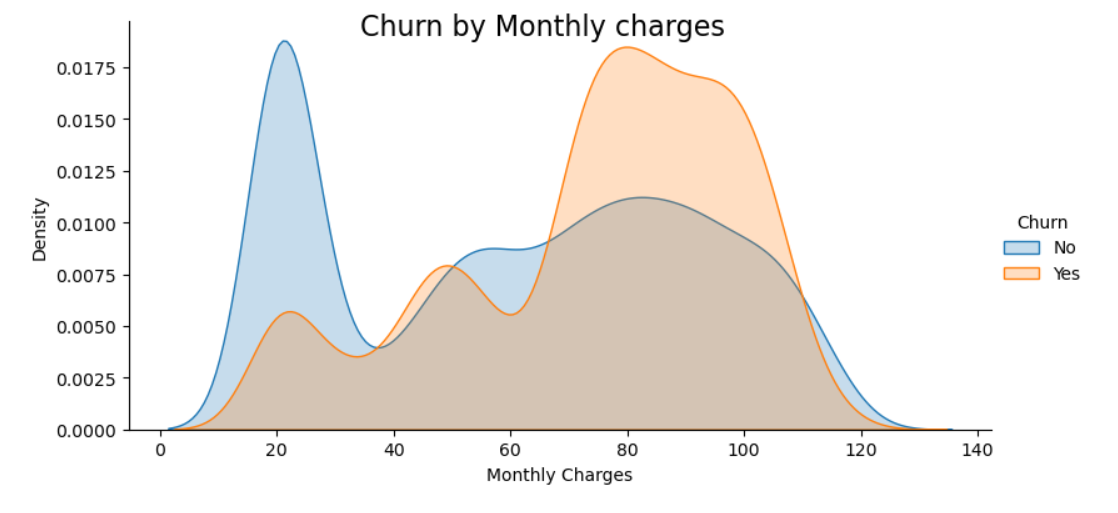
Model Building Steps in Detail
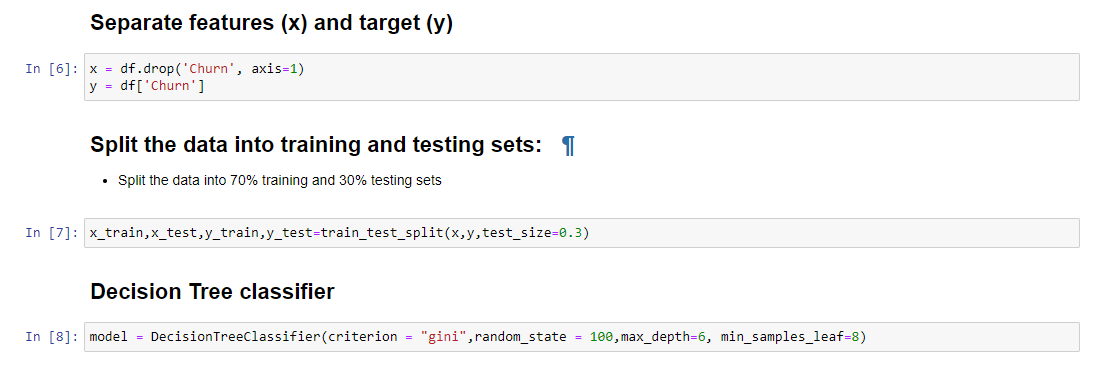
I started by exploring the dataset, which contained information about customer demographics, contract details, services subscribed, and churn status. I performed data cleaning, handled missing values, and visualized key features to gain insights.
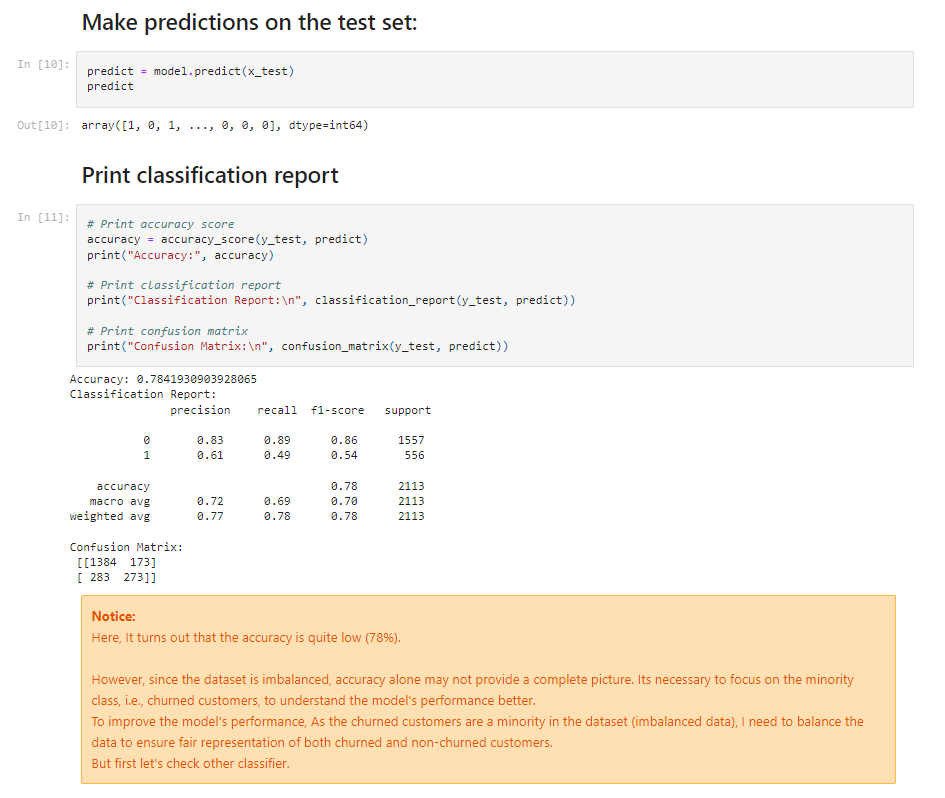
Since the dataset was imbalanced with a churn ratio of 26%, I knew that accuracy alone would not be sufficient to evaluate the models. Hence, I decided to focus on other metrics like recall, precision, and F1 score, especially for the minority class (churned customers).
I experimented with various classifiers, including Random Forest, Gradient Boosting, and K-Nearest Neighbors (KNN). These models showed promising results, but I needed to address the data imbalance issue to improve their performance.
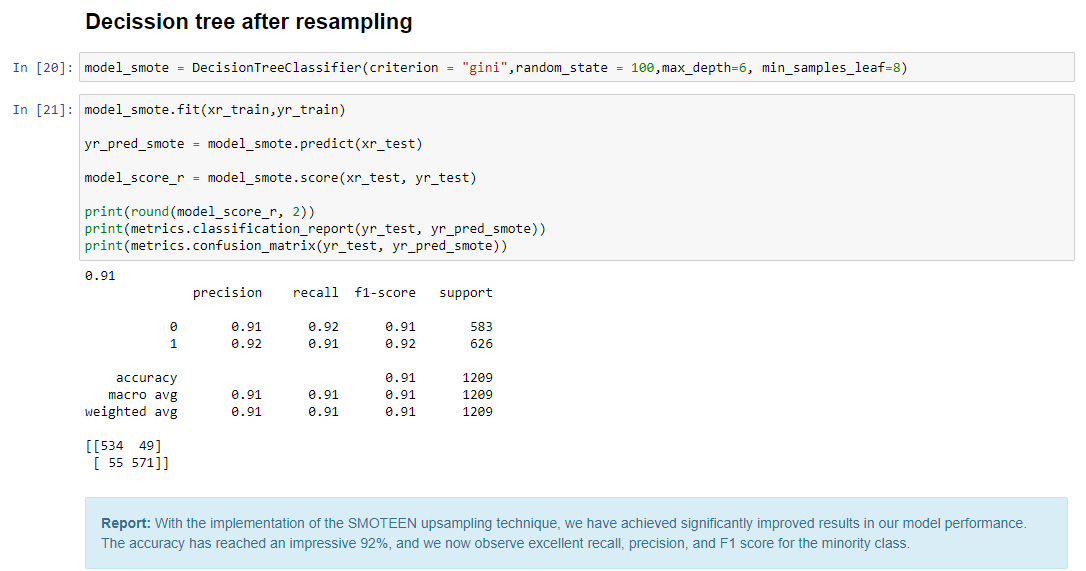
To handle the data imbalance, I employed the SMOTEEN upsampling technique, creating a more balanced dataset with equal representation of churned and non-churned customers.
After upsampling the data, I reevaluated the models' performance using the new balanced dataset. I compared the models' recall, precision, and F1 score for churned customers to identify the most effective one.
Based on the evaluation results, I recommend using the best-performing model to predict customer churn. Additionally, I suggest implementing proactive customer retention strategies based on the model's predictions to reduce churn rates and improve customer satisfaction.
This personal project has given me valuable insights into customer churn prediction and the importance of handling imbalanced datasets. By applying various machine learning techniques, I was able to build a reliable model to aid in customer retention efforts. Gathered customer data from the company's database.


Feel free to explore the code on my GitHub or Jupyter Notebook for EDA , for Machine Learning Model for an in-depth look at the project's implementation.
Hearty Thank You